Nicht selten bekommen in die Jahre gekommene oder strukturell unvorteilhaft gestaltete Websites durch einen Relaunch ein neues Gesicht. Eine veränderte URL-Struktur macht manche URL dann obsolet. Doch in einigen Fällen ist es wichtig, das alte Design nochmals unter die Lupe zu nehmen. Oder alte URLs müssen wiederentdeckt werden – etwa um diese nachträglich weiterzuleiten.
Dann ist die Wayback Machine die Webadresse, die man aufsuchen muss. Mittels diesem Internetarchiv können alte Website-Versionen abgerufen werden. In gewissen Abständen wird durch das Tool der aktuelle Website-Stand gescannt und gespeichert. Gibt man in die Suchmaske die gewünschte Domain ein, wird jede gespeicherte Variante mittels Kalenderansicht angeboten.

Quelle: https://archive.org/web/
Wie lädt man Daten aus der Wayback Machine runter?
Was man bei der Wayback Machine vergeblich sucht, ist der Button, den alten Website-Stand herunterzuladen. Das kann wichtig werden, will man die alte URL-Struktur fein säuberlich in einer Liste zusammenfassen. Auch hier wollen wir wieder auf die womöglich versäumte Weiterleitung alter URLs verwiesen werden.
Dass man die Funktion auf Anhieb nicht findet, heißt noch nicht, dass es gar nicht möglich ist. Wir zeigen, wie man Daten aus der Wayback Machine downloaden kann.
Schritt 1: Website-Daten als JSON- oder TXT-Datei
Zunächst sollte man mit der Wayback Machine die Website-Version identifizieren, die man herunterladen möchte. Hierfür sucht man nach der gefragten Domain und das passende Datum heraus.
Schließlich nutzt man eine der folgenden URLs zur Extrahierung der Daten. Welche URL Anwendung findet, hängt davon ab, ob man eine JSON-Datei oder eine Text-Datei zur Darstellung verwenden möchte.
JSON-Datei:
http://web.archive.org/cdx/search/cdx?url=beispiel.de*&output=json
TXT-Datei:
http://web.archive.org/cdx/search/cdx?url=beispiel.de*&output=txt
Der Platzhalter „beispiel.de“ muss durch die entsprechende Domain ausgetauscht werden. Will man nun einen bestimmten Zeitpunkt abbilden, fügt man das Datum am Ende der URL an.
Etwa wie im folgenden Beispiel:
http://web.archive.org/cdx/search/cdx?url=marmato.de*&output=txt&from=20190212111724
Schließlich erhält man eine Liste mit sämtlichen Daten der Website-Version aus der Wayback Machine.

Schritt 2: Website-Daten der Wayback Machine in Google Sheets kopieren
Die Daten kopiert man nun komplett in eine Google-Sheets-Datei (oder Excel-Datei).
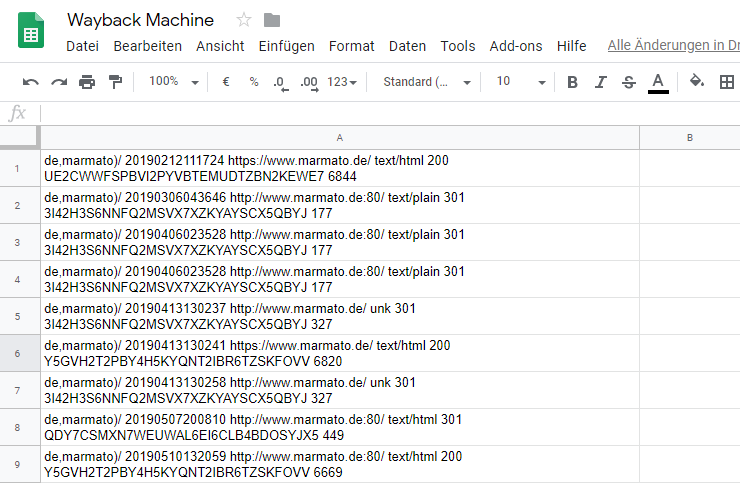
Mithilfe der Funktion „Text in Spalten aufteilen“ stellt man die Daten übersichtlich dar. Nun werden in einem nächsten Schritt alle Spalten außer diejenige mit den URLs entfernt. Im unserem Beispiel ist das die Spalte C.
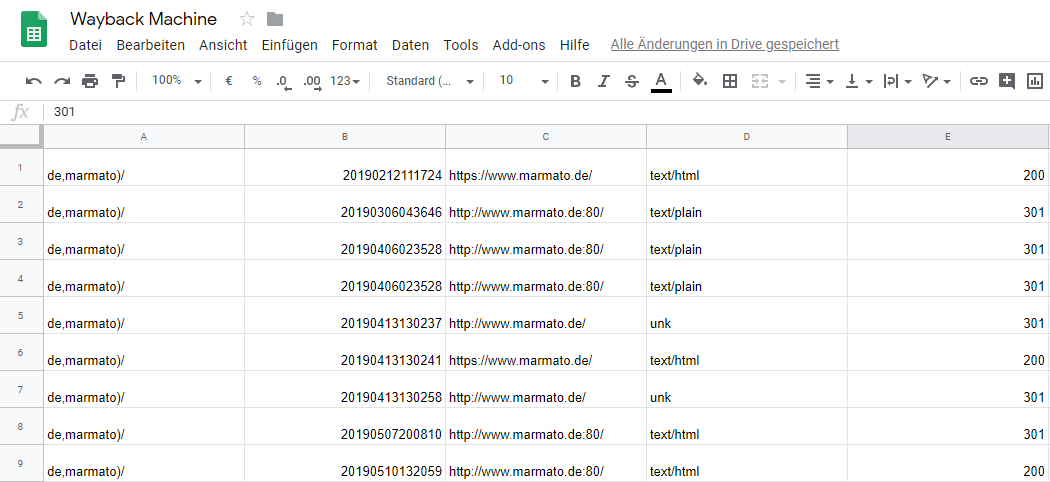
Schritt 3: Suchen und Ersetzen und Duplikate entfernen
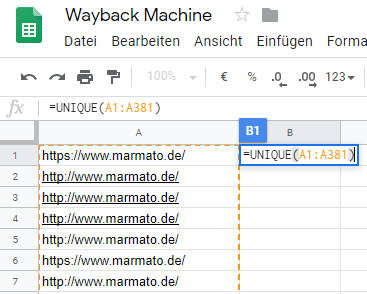
Mithilfe der Suchen-Ersetzen-Funktion wird nun der Zusatz „:80“ gesucht und durch nichts ersetzt. Dieser Zusatz hängt meist an den Daten der Wayback Machine an, hat für den User jedoch keinen Mehrwert. Anschließend sollten mit dem UNIQUE-Befehl Duplikate gelöscht werden. Also zum Beispiel: „=UNIQUE=(A1:A500)“!
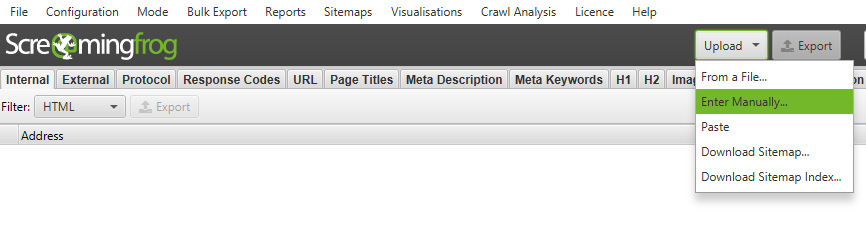
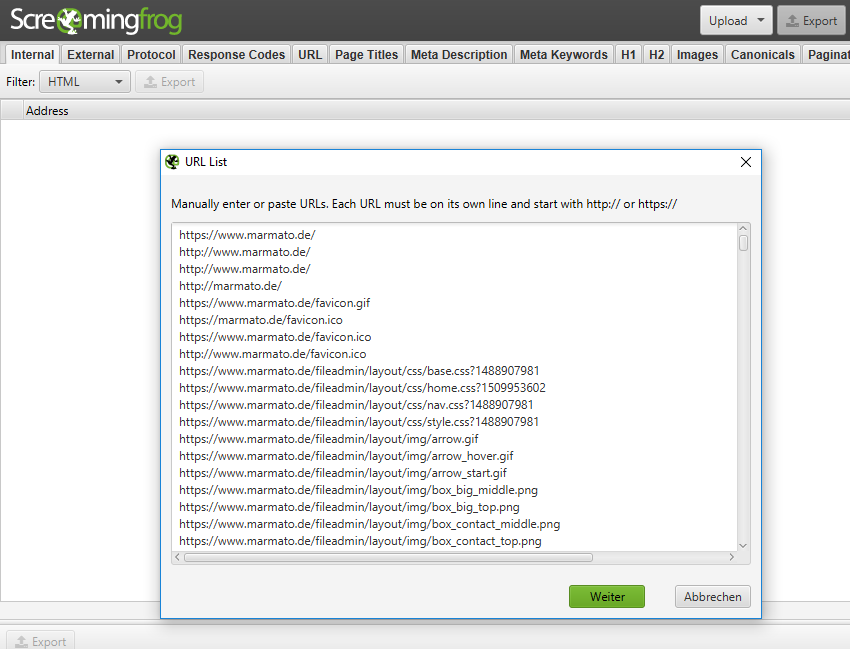
Schritt 4: URLS mittels Screaming Frog crawlen
Nun erhält man alle Dateien, die die Wayback Machine zu der gewählten Website-Version gefunden hat. Will man nun den Status Code der einzelnen Seiten ermitteln, kann man die Liste mit dem Screaming Frog crawlen. Das kann wichtig werden, um zu erfahren, welche Seiten weitergeleitet werden und welche nicht.
Man kann entweder eine zuvor abgespeicherte Datei im Tool Screaming Frog hochladen oder manuell die Liste dort hineinkopieren.
Ob zur Weiterleitung, Dokumentation oder aus gänzlich anderen Gründen – es entsteht in wenigen Schritten und ganz unkompliziert ein perfekt auswertbarer Datensatz der Wayback Machine!







